Key Takeaway
MiniMax M3 is a new open-weight AI model built for coding, agent workflows, long-context tasks, and multimodal input. Its strongest claim is not that it fully beats closed frontier models, but that it brings near-frontier performance, a 1-million-token context window, and lower running costs into an open-weight model that still needs independent testing.

MiniMax M3 – Key Points
The Story
MiniMax released M3 on June 1, 2026, positioning it as an open-weight model for developers, AI agents, coding assistants, research workflows, and long-document analysis.
The model supports text, image, and video input, can handle up to 1 million tokens of context, and is designed for long-running tasks that require tool use, coding, browsing, desktop operation, and multi-step reasoning.
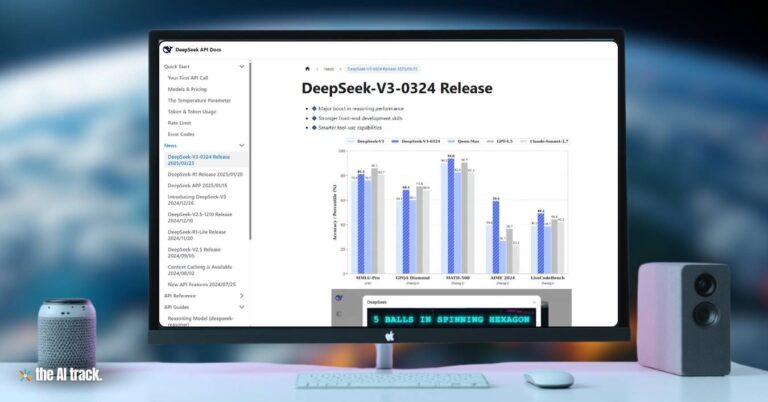
MiniMax says M3 surpasses GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro, a coding benchmark focused on software engineering tasks. The company reports a score of 59.0% for M3, compared with 58.6% for GPT-5.5 and 54.2% for Gemini 3.1 Pro in the benchmark comparison it published.
That margin is narrow. M3 also trails Claude Opus 4.8 on several directly comparable agent benchmarks. The more important point is that an open-weight model is now being positioned close to closed frontier systems on coding and agentic work, while offering lower API pricing and eventual self-hosting options.
The Facts
- Release date: June 1, 2026.
- Model type: Open-weight, multimodal foundation model.
- Main focus: Coding, agentic workflows, tool use, long-context reasoning, desktop operation, and multimodal tasks.
- Context window: Up to 1 million tokens, with a stated minimum support level of 512K tokens.
- Inputs: Text, images, and video.
- Output: Text.
- Availability: API access is live through MiniMax services and third-party providers such as OpenRouter.
- Weights: MiniMax says open weights and a full technical report will be released within about 10 days of launch, with Hugging Face and GitHub listed as expected distribution channels.
- Pricing: API pricing is $0.60 per million input tokens and $2.40 per million output tokens, with a 50% launch discount reducing this to $0.30 input and $1.20 output per million tokens during the first week.
- Subscriptions: MiniMax Code plans start at $20 per month, with higher tiers at $50 and $120 per month.
- Architecture: MiniMax Sparse Attention, or MSA, is designed to reduce compute costs for very long context windows.
What Is New
MiniMax M3 combines three capabilities that usually appear in separate product categories:
Coding and agentic task performance
M3 is designed to work across software engineering, terminal execution, web browsing, tool use, autonomous workflows, and desktop computer operation.
Very long context
The 1-million-token context window means the model can process large codebases, long documents, research papers, logs, video transcripts, or multi-file project material in one session.
Native multimodality
M3 was built to process text, images, and video input, rather than treating visual input as a separate add-on layer.
For users, the practical value is straightforward: M3 is aimed at tasks where the model needs to see more information, keep more context, and act across more steps.
Benchmark Claims
MiniMax reports that M3 scores 59.0% on SWE-Bench Pro, narrowly ahead of GPT-5.5 at 58.6% and Gemini 3.1 Pro at 54.2% in the company’s comparison.
The model also reports:
- 66.0% on Terminal-Bench 2.1
- 70.0% on OSWorld-Verified
- 83.5 on BrowseComp
- 74.2% on MCP Atlas
- Strong performance on SVG generation and multimodal document benchmarks
MiniMax also tested M3 in long-running internal demonstrations. In one example, the model reproduced core experiments from an ICLR 2025 paper over nearly 12 hours, producing 18 commits and 23 experimental figures. In another, it optimized a matrix multiplication kernel on NVIDIA Hopper GPUs over 24 hours, completing 147 benchmark submissions and 1,959 tool calls while improving reported hardware utilization from 7.6% to 71.3%.
Those demonstrations are useful examples of the intended product direction, but they are not controlled benchmark results.
These figures should be treated as early release benchmarks. The benchmark numbers were produced by MiniMax on its own infrastructure, and broader independent testing is still needed across real developer workloads.
The clearest interpretation is this: M3 looks competitive, especially on cost and openness, but it is not a confirmed all-around replacement for the strongest closed models.
Where M3 Still Trails the Current Frontier
M3’s launch comparison looks strongest against GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro. The picture changes when it is compared with Claude Opus 4.8, which was released shortly before M3.
On directly comparable agent benchmarks, M3 trails Claude Opus 4.8:
- SWE-Bench Pro: M3 at 59.0% vs Claude Opus 4.8 at 69.2%
- Terminal-Bench 2.1: M3 at 66.0% vs Claude Opus 4.8 at 74.6%
- OSWorld-Verified: M3 at 70.0% vs Claude Opus 4.8 at 83.4%
That does not make M3 insignificant. It means the model’s strongest argument is not absolute frontier leadership. Its argument is near-frontier capability, open-weight access, long context, multimodal input, and much lower running cost.
How MiniMax Sparse Attention Works
MiniMax Sparse Attention is the architecture behind M3’s long-context capability.
Standard attention becomes expensive as context grows because the model has to compare many tokens against many other tokens. That creates a scaling problem when users move from short prompts to full repositories, long videos, or multi-document workflows.
MSA reduces that cost through a two-stage process. A lightweight index branch first selects relevant blocks from the key-value cache, then the main attention computation runs only on those selected blocks.
MiniMax says this reduces per-token compute at a 1-million-token context to 1/20th of its previous M2 generation. The company also reports approximately 9.7× faster input processing and 15.6× faster response generation at full context length.
Unlike approaches that compress key-value data, MSA works on uncompressed key-value blocks. MiniMax says this helps avoid precision loss at long context lengths.
What You Can Use MiniMax M3 For
MiniMax M3 is most relevant for:
- Reviewing and editing large codebases
- Building coding agents
- Debugging across many files
- Reading long research papers and reproducing experiments
- Working with long videos, transcripts, and document sets
- Building AI assistants that need tool use and multi-step planning
- Analyzing large legal, technical, or business documents
- Running lower-cost AI workflows where closed-model APIs are too expensive
The model is especially interesting for developers, startups, researchers, and small teams that want strong coding and agent capabilities without depending fully on a closed API provider.
Access and Pricing
MiniMax M3 is available through MiniMax’s API services and MiniMax Code. OpenRouter also lists M3 with a 1-million-token context window and launch-discount pricing.
API pricing at launch is $0.60 per million input tokens and $2.40 per million output tokens. A 50% first-week launch discount reduces that to $0.30 per million input tokens and $1.20 per million output tokens.
MiniMax Code also offers subscription plans:
- Plus: $20 per month, with approximately 1.7 billion M3 tokens
- Max: $50 per month, with approximately 5.1 billion M3 tokens
- Ultra: $120 per month, with approximately 9.8 billion M3 tokens
Subscription economics can differ from raw API pricing. Teams planning to use M3 at scale should estimate actual token consumption, context length, output length, retries, and priority access needs before choosing a plan.
The open-weight release is the more important access detail. Once the weights are available, developers should be able to download and self-host the model, subject to hardware requirements, licensing terms, and practical deployment support.
That makes M3 different from closed frontier models. Users are not limited to renting API access if they have the infrastructure to run the model thems.
Why This Matters
MiniMax M3 shows how quickly open-weight models are closing the practical gap with closed frontier systems. For users, developers, and businesses, the shift means more choice, lower costs, less vendor lock-in, and stronger AI tools that can work across larger projects, longer documents, and more complex workflows. It also shows why benchmark claims, data exposure, jurisdiction, and deployment control now matter as much as raw model performance.
This article was drafted with the assistance of generative AI. All facts and details were reviewed and confirmed by an editor prior to publication.

DeepSeek V4 previews V4-Pro and V4-Flash with open weights, 1M context, lower-cost inference and early real-world testing questions.

MiniMax launches M2.5 and M2.5-Lightning AI models with near state-of-the-art coding performance and pricing up to 20× cheaper than Claude Opus 4.6.

MiniMax M2.7 is now open-weight with Hugging Face and NVIDIA NIM access, expanding use of the model for coding, tool use, and office workflows.
Read a comprehensive monthly roundup of the latest AI news!