Key Takeaway
Thinking Machines has previewed Interaction Models, a new class of native multimodal AI systems designed for near-real-time voice, video and text collaboration. The system processes input and output simultaneously, aiming to move AI beyond turn-based chat and closer to a live phone-call-style exchange.

Thinking Machines Previews AI Interaction Models – Key Points
The Story
Thinking Machines has introduced a research preview of Interaction Models, which handle interactivity inside the model rather than through external software scaffolding. The preview centers on TML-Interaction-Small, a 276-billion parameter Mixture-of-Experts model with 12 billion active parameters. The system is designed to listen, speak, see, use tools and coordinate with a background model in real time using a full-duplex design that processes 200ms chunks of input and output. The models are not yet publicly available, with a limited research preview planned in the coming months and a wider release later this year.
The Facts
Interaction Models are designed to move AI beyond turn-based exchanges.
Instead of waiting for a user to finish speaking or typing before responding, the system continuously processes audio, video and text while generating output.
The model uses a full-duplex architecture.
This allows simultaneous input and output, making the experience closer to a phone call than a text chain. It can backchannel, interject or respond while the user is still speaking.
TML-Interaction-Small is a 276-billion parameter MoE model.
The model has 12 billion active parameters. Larger pretrained models are currently too slow for this real-time setting, while larger Interaction Models are planned later this year.
The system processes 200ms chunks of input and output.
This micro-turn design removes artificial turn boundaries and lets the model treat silence, overlap and interruption as part of the conversation context.
The model handles audio, video and text natively.
It uses raw audio signals as dMel and 40×40 image patches through lightweight embedding layers, with components co-trained from scratch inside the transformer.
The design avoids large standalone encoders for audio and video.
The system uses encoder-free early fusion rather than relying on separate components such as Whisper-like audio encoders or standalone text-to-speech-style decoders.
The architecture separates live interaction from deeper reasoning.
The interaction model manages conversation, presence and immediate follow-ups, while a background model handles sustained reasoning, web browsing, tool use and longer-horizon work.
Background results are streamed back into the live conversation.
When the interaction model delegates a task, it sends the full conversation context to the background model and integrates results when appropriate instead of abruptly switching context.
The system supports live translation, visual interjections and chart generation while continuing to listen.
Other capabilities include simultaneous speech, visual proactivity, time-aware reminders, live search, web browsing and generative UI.
TML-Interaction-Small outperformed other real-time systems on FD-bench.
The model scored 77.8 on FD-bench V1.5, compared with 46.8 for GPT-realtime-2.0 minimal and 54.3 for Gemini-3.1-flash-live minimal.
The model reached 0.40 seconds turn-taking latency.
That is roughly the speed of natural human conversation and compares with 1.18 seconds for GPT-realtime-2.0 minimal and 0.57 seconds for Gemini-3.1-flash-live minimal.
The models are not yet available to the public or enterprises.
A limited research preview will open in the coming months to collect feedback, with a wider release planned later this year.
Benchmarks / Evidence Check
FD-bench evaluates interactivity, while additional audio, tool-use, safety and video-audio benchmarks test instruction following, response quality and refusal behavior.
Key metrics include:
- TML-Interaction-Small reached 0.40 seconds turn-taking latency on FD-bench V1.
- GPT-realtime-2.0 minimal reached 1.18 seconds.
- Gemini-3.1-flash-live minimal reached 0.57 seconds.
- TML-Interaction-Small scored 77.8 for average interaction quality on FD-bench V1.5.
- GPT-realtime-2.0 minimal scored 46.8.
- Gemini-3.1-flash-live minimal scored 54.3.
- TML-Interaction-Small scored 82.8% response quality / 68.0% Pass@1 on FD-bench V3 with audio and tools, with the background agent enabled.
- TML-Interaction-Small scored 43.4% on Audio MultiChallenge APR.
- TML-Interaction-Small scored 82.1% on IFEval in VoiceBench.
- TML-Interaction-Small reached 99.0% refusal on Harmbench.
The results apply to a research preview rather than a publicly available product. The real-world experience cannot be independently assessed at scale until external users can test the models.
Use Cases
If Interaction Models become available beyond research access, likely applications include:
- Live customer support with lower latency and more natural backchannel responses.
- Real-time translation that continues while both parties are speaking.
- Industrial or lab monitoring where the model can react to visual cues without waiting for a prompt.
- Physical-task auditing using video input, such as repetition counting, action tracking or protocol monitoring.
- Time-sensitive workflows where the system tracks elapsed time, reminders and live process changes.
- Live search and generative UI where the system can browse, use tools or build interface elements while the conversation continues.
Background / Context
Thinking Machines Lab was founded last year by former OpenAI CTO Mira Murati, with former OpenAI researcher and co-founder John Schulman among the company’s key figures. The company launched Tinker in October 2025 as a managed API for fine-tuning language models.
In July 2025, Thinking Machines raised about $2 billion at a $12 billion valuation in a round led by Andreessen Horowitz, with participation from Nvidia, Accel, ServiceNow, Cisco, AMD and Jane Street. The company has also announced major compute partnerships with Nvidia and Google Cloud.
Why This Matters
Most AI systems still work as turn-based tools: the user sends input, waits, and receives output. Interaction Models make interactivity part of the model itself, which could make AI assistants more useful in live conversations, visual tasks, customer support, translation, tool use and time-sensitive work.
This article was drafted with the assistance of generative AI. All facts and details were reviewed and confirmed by an editor prior to publication.

Thinking Machines Lab signed a multi-year Nvidia partnership to deploy Vera Rubin AI systems, backed by a significant Nvidia investment.
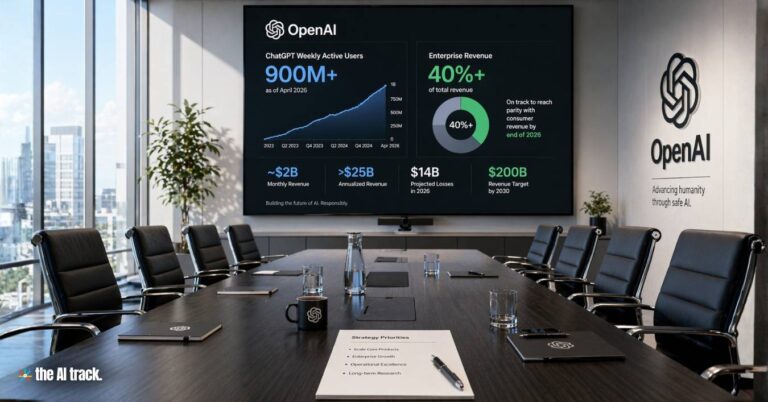
OpenAI loses three senior executives as it shuts down Sora, folds OpenAI for Science into other teams, and pushes harder into enterprise AI.

Mira Murati, CTO of OpenAI, has resigned from her position to pursue personal explorations. Her departure marks a significant shift within the company.
Read a comprehensive monthly roundup of the latest AI news!